Django笔记
常用命令
- django-admin.py startproject projectname 创建项目
- django-admin.py startapp appname 创建应用
- python manage.py migrations 将models变化迁移至migrations
- python manage.py migrate 将migrations变化迁移至数据库
- python manage.py collectstatic 拷贝所有类库及app下的static文件夹至STATIC_ROOT文件夹
- python manage.py createsuperuser 创建超级管理员
- python manage.py runserver 192.168.1.101:80 在对应的IP地址和端口号上运行测试服务器
- pip install django -i https://pypi.douban.com/simple pip更换源
- pip install django --upgrade 升级至最新版本
- pip install django --upgrade -i https://pypi.douban.com/simple pip 使用豆瓣源更新至最新版本
- pip install -r requirements.txt #批量安装 可用 -i 指定源
- pip freeze > requirements.txt 自动生成requirements.txt文件
打印详细的错误原因至控制台
import ast
# convert [1,2,3] to list directly 直接将字符串[1,2,3]转化为list
members = ast.literal_eval(request.POST['members'])
Model相关
ForeignKey
-
是否有值
外键是否有值
-
设置related_name
在不设置的时候默认名称是
ManyToMnay
模型:
# 班级
class MyClass(models.Model):
# 名称
name = models.CharField(max_length=255,
null=True,
verbose_name=u'名称')
# 学员
students = models.ManyToManyField('education.Student',
blank=True,
verbose_name=u'学员')
-
添加、移除
类型对应的操作为
-
批量添加
add一次添加一个queryset时,用法为manytomany.add(*queryset)或者manytomany.set(queryset)
courses = Course.objects.filter(id__in=request.data.getlist('courses'))
interview.pre_student.courses.add(*courses)
-
设置
related_name
在不设置的时候默认名称是
-
反向检索
学员获取自己参加的所有课程:
courses = request.user.prestudent.student.myclass_set.all()
# 以myclass_set为关键字进行反向检索 myclass为类名后面接_set
print(courses) # , , ]>
-
M2M到
self时的问题
示例:
# 部门
class Department(models.Model):
# 部门名称
name = models.CharField(max_length=255,
verbose_name=u'名称')
# 子部门 写成'self'时会出现添加部门1的子部门为部门2时
# 部门2的子部门里也会有部门1的bug
departments = models.ManyToManyField('school.Department',
blank=True,
verbose_name='子部门')
此处子部门 M2M的关联写成'self'时会出现添加部门1的子部门为部门2时,部门2的子部门里也会有部门1的bug。 其实这不是bug,解决方法为 (1)将'self'换成'department.Department' (2) 在departments字段中加入'symmetrical=False',详细介绍见ManyToManyField.symmetrical。
Only used in the definition of ManyToManyFields on self. Consider the following model:
When Django processes this model, it identifies that it has a ManyToManyField on itself, and as a result, it doesn’t add a person_set attribute to the Person class. Instead, the ManyToManyField is assumed to be symmetrical – that is, if I am your friend, then you are my friend.
If you do not want symmetry in many-to-many relationships with self, set symmetrical to False. This will force Django to add the descriptor for the reverse relationship, allowing ManyToManyField relationships to be non-symmetrical.
外键到一个不确定的类的对象
from django.apps import apps
from django.contrib.contenttypes.models import ContentType
from django.contrib.contenttypes.fields import GenericForeignKey
class UnSureModel(models.Model):
# 类的content_type
content_type = models.ForeignKey(ContentType,
null=True,
blank=True,
verbose_name=u'数据来源')
# 对应类型实例ID
object_id = models.PositiveIntegerField(null=True,
blank=True,
verbose_name=u'实例ID')
# 对应的实例
content_object = GenericForeignKey('content_type', 'object_id')
def get_select_object(self):
if self.content_type and self.object_id:
select_model = apps.get_model(app_label=self.content_type.app_label,
model_name=self.content_type.model)
try:
select_object = select_model.objects.get(id=self.object_id)
return select_object
except ObjectDoesNotExist:
return None
else:
return None
DurationField使用
新增时传入timedelta对象:
DRF在新增该字段时是以秒为单位。
bulk_create使用
PostMan发送数据:
choices:{'name':'c', 'content':'sss', 'is_right':False} choices:{'name':'d', 'content':'sssssss', 'is_right':2}
代码:
choices = dict_to_query_dict(request.data).getlist('choices') # 获取choices的list
# list中str转换为dict,dict再转换为Choice类实例,所有的类实例合并为list
# bulk_create入参该list,其内部封装好事务,若其中一个生产错误,则会自动撤销之前操作
choice_list = Choice.objects.bulk_create([Choice(**ast.literal_eval(choice)) for choice in choices])
# PS:bulk_create不会调用实例的save方法,不会发出post_save信号,返回实例无ID,需要再次手动调用save()
for choice in choice_list:
choice.save()
instance = question_serializer.save()
instance.choices.add(*choice_list)
chapter.questions.add(instance)
上述PostMan发送的第二条数据is_right类型错误,无法保存,提示错误:ValidationError: ['’2‘ 必须为 True 或者 False。'],bulk_create方法内部封装好事务,则第一条正确的记录也不会被新增。
金额操作
对金额进行操作时,一律使用DecimalField而不使用FloatFiled。 需要注意的是,DecimalField在模型中设置默认值时,应是:
price = models.DecimalField(default=Decimal(0.00),
max_digits=16,
decimal_places=4,
verbose_name='售价')
而不是
虽然不支持Decimal类型与float类型进行混合操作,则全部转换为Decimal类型再进行四则运算。
from decimal import Decimal
discounted_price = Decimal(self.discount_event.calculate_discount(self.real_price))
self.discounted_event_price = self.real_price - discounted_price
float类型的str转为int,需要先转化为float再转化为int,不可直接转换:
不然会将DecimalField的默认值设置为一个float,在计算时会带来类似TypeError: unsupported operand type(s) for *: 'float' and 'decimal.Decimal'这样的错误。
验证相关
- 限制图片大小
def validate_image_size(value):
"""
限制图片文件大小为2M 2M=2*1024KB=2*1024*1024Byte (Byte既字节)
:param value:文件实例
:return: raise 文件大小超过2MB
"""
if value.size > 2097152:
raise ValidationError(u'文件大小超过2MB')
image = models.ImageField(upload_to=get_image_path,
validators=[validate_image_size],
verbose_name='图片')
- model中使用clean方法去控制一下比较复杂的模型验证
# 收支款项
class IncomeExpense(models.Model):
....
def clean(self):
point, is_created = Point.objects.get_or_create(user=self.user)
if self.pk:
this = IncomeExpense.objects.get(id=self.id)
# 未支付->支付
if this.payment_state == 0 and self.payment_state == 1:
# 收入 使用余额支付
if self.category.income_expense == 0 and self.payment_category.code == 1:
if point.value < self.amount:
raise ValidationError({
'payment_category': '账户余额不足 余额:{} 待支付:{}'.format(point.value, self.amount)})
else:
# 已支付 收入 使用余额支付
if self.payment_state == 1 and self.category.income_expense == 0 and self.payment_category.code == 1:
if point.value < self.amount:
raise ValidationError(
{'payment_category': '账户余额不足 余额:{} 待支付:{}'.format(point.value, self.amount)})
property
比如说现在用户信息中存储了生日的信息,现在需要根据生日去获取年龄,一般方法为定义一个get_age的方法,如下:
class BaseProfile(models.Model):
birthdate = models.DateField()
#...
def get_age(self):
today = datetime.date.today()
return (today.year - self.birthdate.year) - int(
(today.month, today.day) <
(self.birthdate.month, self.birthdate.day))
使用`profile.get_age()`可以获取到对应的用户年龄信息,但是profile.age会更具有可读性也更符合python的编程理念,这时我们就可以使用`property`装饰器来实现这样的功能:
@property
def age(self):
这时我们就可以用`profile.age`来获取用户的年龄信息了。但是`profile`有一个缺点就是和类的内部方法一样无法在ORM中使用。
> Django Design Patterns and Best Practices P45
Cached properties
`cached_property`比对`property`可以缓存计算结果,适合频繁调用的参数或者计算开销过大的参数。
from django.utils.functional import cached_property
#...
@cached_property
def full_name(self):
return "{0} {1}".format(self.firstname, self.lastname)
> Django Design Patterns and Best Practices P45
unique_together其中有Char字段null=True,blank=True
unique_together其中有Char字段null=True,blank=True,导致输入null也会报重复错误,此时将CharField替换为CharNullField字段即可。
# issue null=True和unique=True
# 同时使用会导致空值被判断为相同
class CharNullField(models.CharField):
description = "CharField that stores NULL"
def get_db_prep_value(self, value, connection=None, prepared=False):
value = super(CharNullField, self).get_db_prep_value(value, connection, prepared)
if value == "":
return None
else:
return value
检索相关
queryset内操作
-
get_object_or_404
-
get_or_create
instance, is_created = Model.object.get_or_create(name='my_name')
instance为新增或者读取到的实例,is_created代表是否是新建的instance。
-
求querySet某一字段的和
Annotate adds a field to results:
>> Order.objects.annotate(total_price=
>
>
>('price'))
, ]>
>> orders.first().total_price
Decimal('340.00')
Aggregate returns a dict with asked result:
eg:
from django.db.models import Sum
current_arrange_hours = class_schedule_my_draft.aggregate(Sum('hours'))['hours__sum']
方法返回的是dict对象,键的名称为 求和字段名__sum,获取该dict对象,取值即可得到和。
-
update()方法注意事项
QuerySet的update()方法会直接生成SQL表达式,不会调用模型的save()方法。
Be aware that the update() method is converted directly to an SQL statement. It is a bulk operation for direct updates. It doesn’t run anysave() methods on your models, or emit the presave or postsave signals (which are a consequence of calling save()), or honor the auto_now field option. If you want to save every item in a QuerySet and make sure that the save() method is called on each instance, you don’t need any special function to handle that. Just loop over them and call save():
-
annotate和aggregate函数
aggregate(聚合)生成的新参数直接加入queryset的属性中,而annotate(备注)是针对queryset中的每个item新增一个属性,其作用对象不同。
需要注意,在queryset使用annotate和aggregate之前,若是使用了filter或者exclude,filter和exclude中的检索条件会被相应的考虑到annotate和aggregate函数之中,若把filter和exclude放在annotate和aggregate函数的后面执行则不会有影响,详见此处。
示例:
from django.db.models import Count
tags = [1, 2]
similar_posts = Message.objects.filter(tag__in=tags)
similar_posts = similar_posts.annotate(same_tags=Count('tag'))
for x in similar_posts:
print(x.id, x.same_tags, x.tag.all())
13 1 , ]>
14 2 , , ]>
可见ID为13的message真正有2个标签,但是符合filter中条件的只有1个;ID为14的message真正有3个标签,符合filter中条件的只有2个。
可见删除filter后得到的标签总和才是Message包含的真正标签数量。
-
values_list去重
distinct函数必须和order_by配合才生效,order_by在distinct之前之后都可以。
Craft.objects.values_list('stage_num', flat=True).distinct()
Craft.objects.values_list('stage_num', flat=True).distinct().order_by('stage_num')
-
queryset获取外键列表
# fk_ids = [x.fk.id for x in instance.items.all()]
fk_ids = instance.items.values_list('fk_id', flat=True)
FK.objects.filter(id__in=fk_ids).all()
先获取外键ID列表,被注释的方法耗时为0.0020s,未注释的方法耗时为0:00:00,推荐使用未注释的方法,不用遍历列表,直接由数据库操作获取外键ID列表,耗时更低也更为简洁。
-
自定义Manager
# 公开文章Manager
class PublicManager(models.Manager):
def get_queryset(self):
return super(PublicManager, self).get_queryset().filter(is_public=True)
# 文章
class Article(models.Model):
is_public = models.BooleanField(default=False, verbose_name='公开')
objects = models.Manager()
public = PublicManager()
获取公开的文章时直接访问Article.public.all()即可,不需要使用Article.objects.filter(is_public=True),使用起来更方便。
如何在 search_fields 中包含外键字段
当 search_fields 包含外键字段时,此时进行搜索会报错Related Field got invalid lookup: icontains,解决的办法是修改 search_fields 中的外键字段名称。将 search_fields 中的外键字段改为 foreign_key__related_fieldname 这种形式就可以了。 这种用法适用于 ForeignKey 及 ManyToManyField 。
class Content(models.Model):
# 对应商品
goods = models.ForeignKey('goods.Goods',
related_name='content_goods',
on_delete=models.CASCADE,
verbose_name='商品')
# 商品包含的含量名
category = models.ForeignKey('goods.Category',
related_name='content_category',
on_delete=models.CASCADE,
verbose_name='含量名')
# 含量名对应的含量值 max_digits减decimal_places为整数部分支持的最大位数
value = models.DecimalField(default=0.00,
max_digits=10,
decimal_places=3,
verbose_name='含量值')
# 商品单位
unit = models.CharField(max_length=255,
verbose_name='含量单位')
admin:
class ContentAdmin(admin.ModelAdmin):
search_fields = ('goods__name', 'category__name',)
list_filter = ('goods__name', 'category__name',)
list_display = ('goods', 'category', 'value', 'unit')
admin.site.register(Content, ContentAdmin)
queryset间操作
-
queryset相减
有父分类的所有含量 减去 该商品已有的含量 作为待选的含量集:
category_list = Category.object.filter(parent__isnull=False).exclude(pk__in=goods.category.all()).all()
-
queryset相加
queryset = queryset1 | queryset2
注意,|操作会对两个queryset间的重复部分进行去重。
实现原理: 某一天发现了一个奇怪的问题,如下: 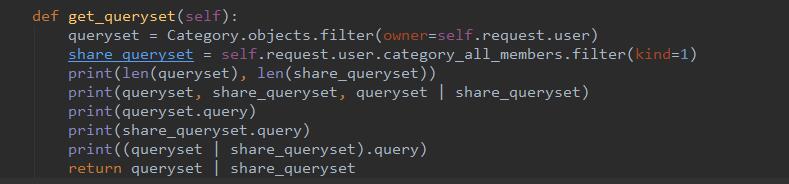 输入如下:
输入如下: 
一个长度为2的queryset和一个长度为0的queryset合并得到了一个长度为3的queryset,检索其query语句才发现这是有可能的,需要对得到的结果再次去重。本质上|操作是对sql语句进行OR,其实现代码如下:
models/query.py:
def __or__(self, other):
self._merge_sanity_check(other)
if isinstance(self, EmptyQuerySet):
return other
if isinstance(other, EmptyQuerySet):
return self
combined = self._chain()
combined._merge_known_related_objects(other)
combined.query.combine(other.query, sql.OR)
return combined
migrations文件冲突
# 合并多个migrations文件至一个
python manage.py squashmigrations app_name 0015
# 有conflicting时合并
python manage.py makemigrations –merge
migrate --fake
Url相关
-
重定向
重定向是指将当前的url发送/转译为其它url再进行处理,而不是指返回的url,不能用于页面刷新。
-
正则
url(r'author/(?P[0-9]+)/$', AuthorUpdate.as_view(), name='author-update'),
url(r'author/(?P\d+)/$', AuthorUpdate.as_view(), name='author-update'),
View相关
-
render函数
return render(request,template,data)
-
动态
success_url
-
基类继承信息时,基类要优先继承,不然不起作用
class BaseMixin(View):
def get_context_data(self, **kwargs):
kwargs['example'] = 'example'
return super(BaseMixin, self).get_context_data(**kwargs)
class NewsUpdateView(BaseMixin, UpdateView): # 有用 example在页面中可以显示
class NewsUpdateView(UpdateView, BaseMixin): # 没用 example在页面中不可显示
-
ListView中queryset使用陷阱
class NewsAllListView(ListContextMixin, ListView):
queryset = News.objects.language('all').in_current_lang().order_by('-id')
template_name = 'news/list_all.html'
context_object_name = 'news_list'
paginate_by = settings.PAGE_NUM
# def get_queryset(self):
# return News.objects.language('all').in_current_lang().order_by('-id')
写成员变量queryset
runserver时输出,输出来源于in_current_lang(),该方法用于限制当前语言环境,in_current_lang只会在runserver时被调用一次,之后就算修改了语言环境,queryset成员变量也不会再次根据语言环境进行调整,只有当再次重启服务器时才会调整语言环境,优点是加载快,但是无法实现语言环境的变化。
, , ]>
, ]>
System check identified no issues (0 silenced).
July 18, 2017 - 10:38:29
Django version 1.11.2, using settings 'Portal.settings'
Starting development server at http://0.0.0.0:80/
Quit the server with CTRL-BREAK.
Performing system checks...
写成员方法get_queryset时,每次都会根据语言环境去调整queryset来源,缺点是开销比写成员变量大,runserver后输出,每次请求该listview in_current_lang都会被调用:
System check identified no issues (0 silenced).
July 18, 2017 - 10:42:47
Django version 1.11.2, using settings 'Portal.settings'
Starting development server at http://0.0.0.0:80/
Quit the server with CTRL-BREAK.
2017-07-18 10:42:52,375 [INFO]- "GET /manage/ HTTP/1.1" 200 6224
2017-07-18 10:42:52,442 [INFO]- "GET /manage/home/ HTTP/1.1" 200 1412
2017-07-18 10:42:52,788 [INFO]- "GET /static/images/favicon.ico HTTP/1.1" 200 1099
, , ]>
, ]>
Form相关
-
使用预设的错误
class LoginForm(forms.Form):
error_messages = {
'login_error': "账户名或密码输入错误",
}
raise forms.ValidationError(self.error_messages["login_error"])
-
动态添加错误
Template相关
-
渲染变量至html
在界面中将某个变量渲染成为html有两种方法:
{% autoescape off %} {{content}} {% endautoescape %}-
{{content|safe}} -
templet常用过滤器
{{ solution.title|truncatechars:20 }} # 20个字符后显示...
{{ solution.create_time|date:"Y-m-d H:i:s" }} # datatime格式
-
检测用户是否有某项权限
perms是一个django.contrib.auth.context_processors.PermWrapper对象,文档见此。 若使用get_template来渲染页面时需要perms对象:
from django.template.loader import get_template
from django.contrib.auth.context_processors import PermWrapper
for article in article_list:
html += get_template('article/article_item.html').render({'article': article,
'perms': PermWrapper(request.user)})
-
传递boolean至js
-
传递list至js
-
绝对路径生成
-
生成本页的绝对路径
{{ request.build_absolute_uri }} - 生成有
url name的url的绝对路径{% absurl 'web_news_detail' news.id %} - 生成静态文件对应的绝对路径
{{ news.cover.url|absolute_media_url:request }}
使用的模板标签文件 在模板中使用时务必使用{% load absolute_url %}加载标签 absolute_url.py:
from django.template import Library
from django.template.defaulttags import URLNode, url
from urllib.parse import urlencode
register = Library()
class AbsoluteURL(str):
pass
class AbsoluteURLNode(URLNode):
"""生成绝对路径的url标签"""
def render(self, context):
asvar, self.asvar = self.asvar, None
path = super(AbsoluteURLNode, self).render(context)
request = context['request']
abs_url = AbsoluteURL(request.build_absolute_uri(path))
# 保持request parameters不丢失
parameters = urlencode(request.GET, doseq=True)
if parameters:
abs_url = '{}?{}'.format(abs_url, parameters)
if not asvar:
return str(abs_url)
else:
if path == request.path:
abs_url.active = 'active'
else:
abs_url.active = ''
context[asvar] = abs_url
return ''
@register.tag
def absurl(parser, token):
node = url(parser, token)
return AbsoluteURLNode(
view_name=node.view_name,
args=node.args,
kwargs=node.kwargs,
asvar=node.asvar
)
@register.filter
def absolute_url(url, request):
"""
Usage: {{ url|absolute_url:request }}
"""
return request.build_absolute_uri(url)
-
Django-filter
filter.qs为过滤后的queryset; filter.data为当前过滤取得的数据,如filter.data.category既为当前取得的类型ID。
-
自定义Tags
示例Tags的作用是高亮当前Navbar选中的选项。
(1) 新建templatetags文件夹,放入空的__init__.py文件。
(2) app/templatetags/nav.py:
from django.core.urlresolvers import resolve
from django.template import Library
register = Library()
@register.simple_tag
def active_nav(request, url):
url_name = resolve(request.path).url_name
if url_name == url:
return "active"
return ""
(3) 用法 {% active_nav request 'pattern_name' %}
分页
使用paginate_by设置每页可显示的个数:
# Goods列表
class GoodsListView(ListView):
queryset = Goods.objects.all()
context_object_name = 'goodsList'
paginate_by = 2
template_name = 'goods/list.html'
使用page_obj变量来显示分页 goods/list.html:
{ % block content %}
< !--分页 -->
{ % if page_obj %}
{ % include
"include/pagination.html" %}
{ % endif %}
{ % endblock %}
paginate.html:
<ul class="pagination">
{% if page_obj.has_previous %}
<li><a href="?page={{page_obj.previous_page_number}}">«</a></li>
<li><a href="?page={{page_obj.previous_page_number}}">{{page_obj.previous_page_number}}</a></li>
{% else %}
<li class="disabled"><a href="#">«</a></li>
{% endif %}
<li class="active"><a href="?page={{page_obj.number}}">{{page_obj.number}}</a></li>
{% if page_obj.has_next%}
<li>
<a href="?page={{page_obj.next_page_number}}">{{page_obj.next_page_number}}</a>
</li>
<li>
<a href="?page={{page_obj.next_page_number}}">»</a>
</li>
{% else %}
<li class="disabled">
<a href="#">»</a>
</li>
{% endif %}
</ul>
- page_obj.has_previous 是否有上一页
- page_obj.has_next 是否有下一页
- page_obj.previous_page_number 上一页页码
- page_obj.next_page_number 下一页页码
- page_obj.number 当前页码
- paginator.num_pages 总页码数
Admin相关
-
方法结果显示在list中
-
写在
admins.py中:# 试听 class AuditionAdmin(admin.ModelAdmin): list_display = ['id', 'pre_student', 'follower', 'course', 'teacher', 'class_room', 'state', 'feed_back_staff', 'feed_back_time'] list_filter = ('state', ) # 横向过滤器 def course(self, obj): #list_display 外键 return obj.class_schedule.course course.short_description = '课程' -
写在
models.py中: -
设置字段只读
可见但不接修改
-
设置字段不出现在admin中
则在
字段中设置
即可
-
修改SuperUser密码
-
设置站点admin显示title
-
设置app的
verbose_name
apps.py:
__init__.py:
-
设置model的verbose_name
models.py
-
设置列表可编辑字段
设置
即可一次编辑列表上多行数据对应的某些字段,但是要求这些字段都在
中。
Utils相关
-
字符拼接
-
'数字:%d 字符串 %s'%(instance.pk,instance.name)
- 单个变量时后面可不用括号,如:'字符串:%s'%instance.name
- '{}{}'.format(str1, str2) 优于使用%
-
'{one}{two}'.format(one=str1, two=str2)
-
页面间消息传递
Django的message框架可以用来传递页面之间的消息
-
判断str是否为数字
封装后:
def isdigit(string):
"""
:param string:
:return: 该字符是否是数字
"""
if isinstance(string, int):
return True
else:
return isinstance(string, str) and string.isdigit()
-
由数据库表名称获取对应的model
from django.apps import apps
model = next((m for m in apps.get_models() if m._meta.db_table == 'family_smstemplate'), None)
print(model)
-
字符串连续定义
避免写多行,更简洁。
subject, from_email, to = 'hello', settings.EMAIL_HOST_USER, '614457662@qq.com'
-
Python类型判断
class Foo(object):
pass
class Bar(Foo):
pass
print type(Foo()) == Foo True
print type(Bar()) == Foo False
print isinstance(Bar(),Foo) True
type不会认为子类是一种父类类型,isinstance会认为子类是一种父类类型。
信号
-
request_finished
from django.core.signals import request_finished
from django.dispatch import receiver
@receiver(request_finished)
def my_callback(sender, **kwargs):
print("Request finished!")
from django.dispatch import Signal
request_started = Signal(providing_args=["environ"])
request_finished = Signal()
got_request_exception = Signal(providing_args=["request"])
setting_changed = Signal(providing_args=["setting", "value", "enter"])
-
自定义信号
from django.dispatch import receiver
post_viewed = django.dispatch.Signal(providing_args=["post", "request"])
@receiver(post_viewed)
def handle_post_viewed(sender, **kwargs):
print('------------------')
# 用户
class UserViewSet(ModelViewSet):
queryset = UserMessage.objects.all()
serializer_class = UserSerializer
@list_route(methods=['GET'])
def sender(self, request):# 发出信号
post_viewed.send(sender=self.__class__)
return Response('sender')
@list_route(methods=['GET'])# 不发出信号
def receiver(self, request):
return Response('')
-
pre_save
it's used before the transaction saves.
-
post_save
it's used after the transaction saves.
from django.dispatch import receiver
from django.db.models.signals import post_save
@receiver(post_save, sender=settings.AUTH_USER_MODEL)
def user_create(sender, instance=None, created=False, **kwargs):
if created:
member = Member.objects.create(user=instance)
family = Family.objects.create()
family.members.add(member)
-
信号不触发问题
新建signals.py文件写信号相关的代码时,需要在apps.py中新增ready函数
不然会导致signals.py中的代码无法生效。而且必须要用import user.signals导入而不可用from .signals import *导入,不然会提示SyntaxError: import * only allowed at module level错误。
测试
-
测试驱动开发
既在写功能代码前,优先写测试代码,虽然与直觉相悖,但是这与一般人做事的顺序相同,先发现问题,再写代码去解决这个问题,只是测试驱动开发把这个过程形式化了。
-
测试函数
函数必须以小写的test开头,各个测试之间要独立,调用的顺序为函数名的字母顺序,每个测试函数测试完成后数据库将自动回滚至初始状态。
-
Pycharm中运行测试的注意事项
鼠标指针位于测试案例的某个函数的作用域内将只执行这个函数,位于测试案例的作用域内将执行整个测试案例。
-
设置断点
之后在控制台将看到(Pdb):,可以输入Python语句进行交互检查。
第三方工具及作用简介
-
django-celery
异步发送邮件、处理任务使用库
其他
-
定义类内部方法
双下划线(double undersocres)用户定义类的内部属性 用于定义只可在类的内部使用的参数和方法
-
三目运算精简代码
state = True if day == date else False
等价于:
-
request.data类型是Dict不是QueryDict
使用requests库直接向Django发起请求时,服务器接收到的request.data类型是Dict不是QueryDict,会导致request.data的getlist方法无法使用。解决方法:
-
直接判断类型 dict类型时使用dict['name'],QueryDict类型时使用querydict.getlist('name'), PS:dict['name']等价于querydict.getlist('name')
-
进行类型转换 Django1.11如下:
from django.http import QueryDict from django.utils.datastructures import MultiValueDict
data = QueryDict('', mutable=True) data.update(MultiValueDict(request.data)) print(data.getlist('id')) def dicttoquery_dict(dict): """ requests库请求时request.data为dict 需要转换为querydict才能使用getlist方法 :param dict: dict :return: query*dict """ query*dict = QueryDict('', mutable=True) querydict.update(MultiValueDict(dict)) return querydict
data = dicttoquery_dict(request.data) if isinstance(request.data, dict) else request.data items = data.getlist('items')
MultiValueDict介绍如下:
class MultiValueDict(dict):
"""
A subclass of dictionary customized to handle multiple values for the
same key.
>>> d = MultiValueDict({'name': ['Adrian', 'Simon'], 'position': ['Developer']})
>>> d['name']
'Simon'
>>> d.getlist('name')
['Adrian', 'Simon']
>>> d.getlist('doesnotexist')
[]
>>> d.getlist('doesnotexist', ['Adrian', 'Simon'])
['Adrian', 'Simon']
>>> d.get('lastname', 'nonexistent')
'nonexistent'
>>> d.setlist('lastname', ['Holovaty', 'Willison'])
This class exists to solve the irritating problem raised by cgi.parse_qs,
which returns a list for every key, even though most Web forms submit
single name-value pairs.
"""
requets发起请求:
import requests
data = {'id': [7, 8], 'ss': 'sss'}
print(type(data))
print(data)
r = requests.post(url='http://192.168.1.108/purchase_courses/test/', json=data,
headers={'Authorization': 'Token 75xxxxxxxxxxxxxxxxxxxxxfb4'})
print(r.text)
原生sql防注入
c=db.cursor()
max_price=5
c.execute("""SELECT spam, eggs, sausage FROM breakfast
WHERE price < %s""", (max_price,))
而不是
Python best practice and securest to connect to MySQL and execute queries